基于朴素贝叶斯的个人信用评估
一、实验环境
下载数据集,使用本地 jupyter notebook, python3 完成实验。将 jupyter notebook 导出为 markdown ,编辑之后使用 pandoc 直接转为 word
二、数据预处理
使用
pandas数据读取读取数据
1
2
3import pandas as pd
credit = pd.read_csv('./input/credit.csv')
credit.head(5)显示数据

查看数据规模
1
credit.shape
1
(1000, 21)
查看数据种类
1
credit.dtypes.value_counts()
1
2
3object 13
int64 8
dtype: int64可见非数值列有 $ 13 $ 列,数值列有 $ 8 $ 列
非数值型数据处理
对数值型数据进行描述性统计
1
credit.select_dtypes('object').describe()
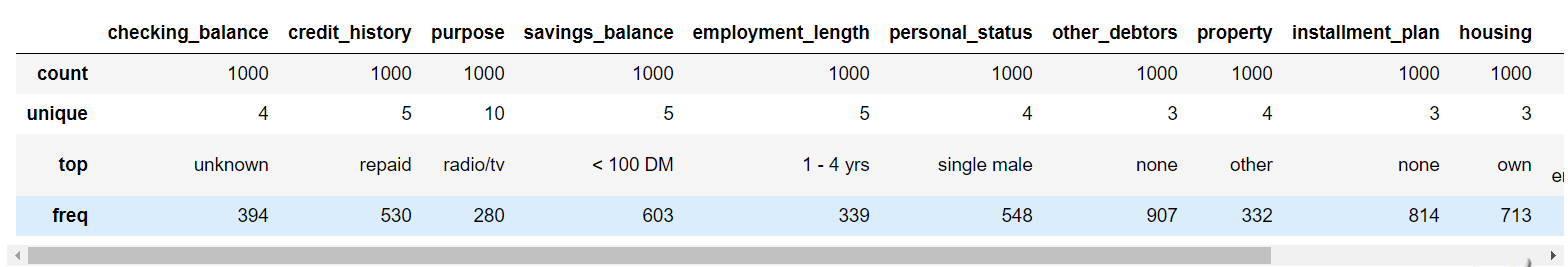
查看非数值型特征的缺失情况
1 | credit.select_dtypes('object').isnull().sum() |
checking_balance 0
credit_history 0
purpose 0
savings_balance 0
employment_length 0
personal_status 0
other_debtors 0
property 0
installment_plan 0
housing 0
job 0
telephone 0
foreign_worker 0
dtype: int64
可以看到没有缺失值,缺失个数都是 $ 0 $
查看非数值列的数据种类信息
1
for col in credit.select_dtypes('object'): print('-' * 50) print(credit[col].value_counts())
--------------------------------------------------unknown 394< 0 DM 2741 - 200 DM 269> 200 DM 63Name: checking_balance, dtype: int64--------------------------------------------------repaid 530critical 293delayed 88fully repaid this bank 49fully repaid 40Name: credit_history, dtype: int64--------------------------------------------------radio/tv 280car (new) 234furniture 181car (used) 103business 97education 50repairs 22others 12domestic appliances 12retraining 9Name: purpose, dtype: int64--------------------------------------------------< 100 DM 603unknown 183101 - 500 DM 103501 - 1000 DM 63> 1000 DM 48Name: savings_balance, dtype: int64--------------------------------------------------1 - 4 yrs 339> 7 yrs 2534 - 7 yrs 1740 - 1 yrs 172unemployed 62Name: employment_length, dtype: int64--------------------------------------------------single male 548female 310married male 92divorced male 50Name: personal_status, dtype: int64--------------------------------------------------none 907guarantor 52co-applicant 41Name: other_debtors, dtype: int64--------------------------------------------------other 332real estate 282building society savings 232unknown/none 154Name: property, dtype: int64--------------------------------------------------none 814bank 139stores 47Name: installment_plan, dtype: int64--------------------------------------------------own 713rent 179for free 108Name: housing, dtype: int64--------------------------------------------------skilled employee 630unskilled resident 200mangement self-employed 148unemployed non-resident 22Name: job, dtype: int64--------------------------------------------------none 596yes 404Name: telephone, dtype: int64--------------------------------------------------yes 963no 37Name: foreign_worker, dtype: int64 可以发现出现了许多的 unknown ,应该是原数据的 Nan 已经通过哑变量的方法替换为了 unknown
查看非数值列数据种类数
1
for col in credit.select_dtypes('object'): print("列名:" + col + ", 有", credit[col].value_counts().shape[0], "种类型")
1 | 列名:checking_balance, 有 4 种类型列名:credit_history, 有 5 种类型列名:purpose, 有 10 种类型列名:savings_balance, 有 5 种类型列名:employment_length, 有 5 种类型列名:personal_status, 有 4 种类型列名:other_debtors, 有 3 种类型列名:property, 有 4 种类型列名:installment_plan, 有 3 种类型列名:housing, 有 3 种类型列名:job, 有 4 种类型列名:telephone, 有 2 种类型列名:foreign_worker, 有 2 种类型 |
非数值型数据列数比较多,但是每一列的类别比较少,最多只有 $ 5 $ 种类别,可以直接看做离散特征
将非数值数据进行编码,这里直接像之前一样,使用数字编码
1 | col_dicts = {}cols = list(credit.columns) # 这里还是直接使用所有列,后面进行一次判断col_dicts = {'checking_balance': {'1 - 200 DM': 2, '< 0 DM': 1, '> 200 DM': 3, 'unknown': 0}, 'credit_history': {'critical': 0, 'delayed': 2, 'fully repaid': 3, 'fully repaid this bank': 4, 'repaid': 1}, 'employment_length': {'0 - 1 yrs': 1, '1 - 4 yrs': 2, '4 - 7 yrs': 3, '> 7 yrs': 4, 'unemployed': 0}, 'foreign_worker': {'no': 1, 'yes': 0}, 'housing': {'for free': 1, 'own': 0, 'rent': 2}, 'installment_plan': {'bank': 1, 'none': 0, 'stores': 2}, 'job': {'mangement self-employed': 3, 'skilled employee': 2, 'unemployed non-resident': 0, 'unskilled resident': 1}, 'other_debtors': {'co-applicant': 2, 'guarantor': 1, 'none': 0}, 'personal_status': {'divorced male': 2, 'female': 1, 'married male': 3, 'single male': 0}, 'property': {'building society savings': 1, 'other': 3, 'real estate': 0, 'unknown/none': 2}, 'purpose': {'business': 5, 'car (new)': 3, 'car (used)': 4, 'domestic appliances': 6, 'education': 1, 'furniture': 2, 'others': 8, 'radio/tv': 0, 'repairs': 7, 'retraining': 9}, 'savings_balance': {'101 - 500 DM': 2, '501 - 1000 DM': 3, '< 100 DM': 1, '> 1000 DM': 4, 'unknown': 0}, 'telephone': {'none': 1, 'yes': 0}}for col in cols: if credit[col].dtypes == object: # 判断是非数值列 credit[col] = credit[col].map(col_dicts[col])credit.head(5) |

对数值型数据处理
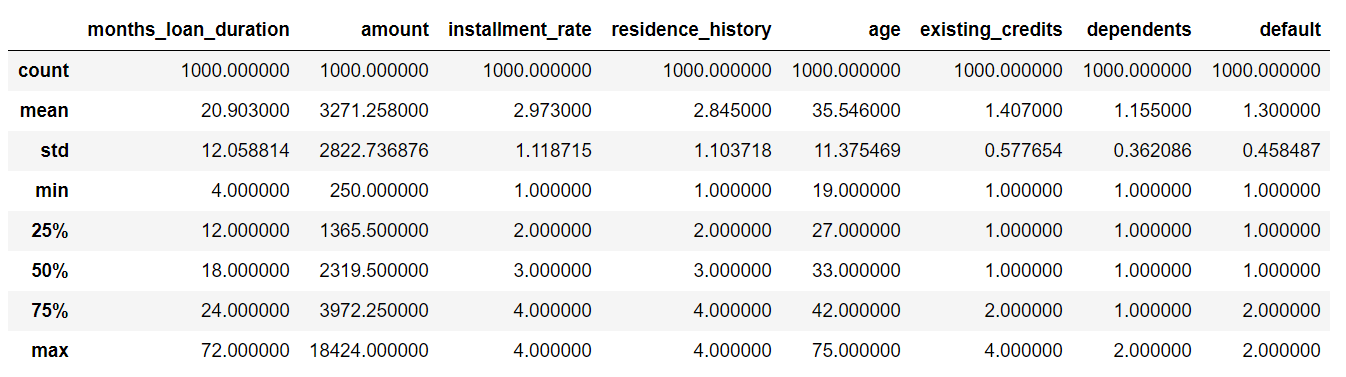
对数值型数据进行描述性统计
1
credit.describe()
查看数值型数据缺失情况
1
credit.select_dtypes('int64').isnull().sum()
months_loan_duration 0amount 0installment_rate 0residence_history 0age 0existing_credits 0dependents 0default 0dtype: int64可见所有的数值列全部没有缺失值,不需要进行缺失值填补
查看数值型数据每列的种类数
1 | for col in credit.select_dtypes('int64'): print("列名:" + col + ", 有", credit[col].value_counts().shape[0], "种类型") |
1 | 列名:months_loan_duration, 有 33 种类型列名:amount, 有 921 种类型列名:installment_rate, 有 4 种类型列名:residence_history, 有 4 种类型列名:age, 有 53 种类型列名:existing_credits, 有 4 种类型列名:dependents, 有 2 种类型列名:default, 有 2 种类型 |
可以看到 months_loan_duration, amount, age 连续性比较明显,而且方差比较高,需要进行离散化处理。这里我使用 Kmeans 聚类离散化。其他的列本身就是离散值,没有进行特别的处理
1
from sklearn.cluster import KMeansimport matplotlib.pyplot as pltfrom sklearn.metrics import silhouette_scorefrom sklearn import preprocessingimport matplotlib as mplimport numpy as npfrom scipy.spatial.distance import cdistmpl.rcParams['font.sans-serif'] = ['KaiTi', 'SimHei', 'FangSong'] # 汉字字体,优先使用楷体,如果找不到楷体,则使用黑体mpl.rcParams['font.size'] = 12 # 字体大小mpl.rcParams['axes.unicode_minus'] = False # 正常显示负号data_col = ['months_loan_duration', 'amount', 'age']
因为需要使用kmeans首先需要数据标准化,这里使用 Z-score 标准化方法。发现因为只对单列进行 K-means ,所以感觉标准化不太必要
1 | data_col_zscore = pd.DataFrame(preprocessing.scale(credit[data_col]),columns=credit[data_col].columns)data_col_zscore.head(5) |

使用肘部法则 SSE 确定 K-means 中 K 的大小
1
for col in data_col: col = data_col_zscore[col] s = col.values.reshape(len(col), 1) K=range(1,20) sse_result=[] for k in K: kmeans=KMeans(n_clusters=k) kmeans.fit(s) sse_result.append(sum(np.min(cdist(s,kmeans.cluster_centers_,'euclidean'),axis=1))/s.shape[0]) plt.plot(K,sse_result,'gx-') plt.xlabel('k') plt.ylabel(u'平均畸变程度') plt.title(u'肘部法则确定' + col.name + '最佳的K值') plt.show()

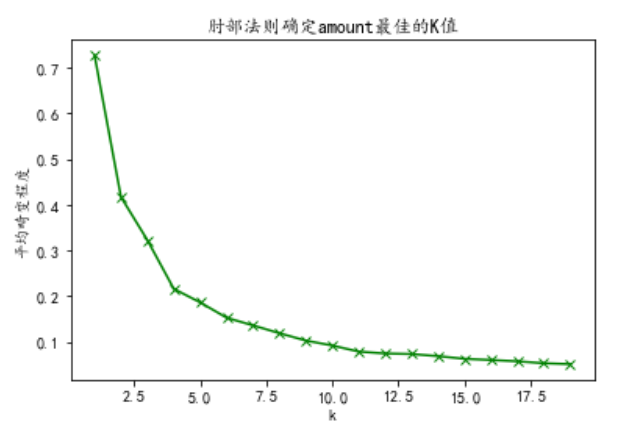
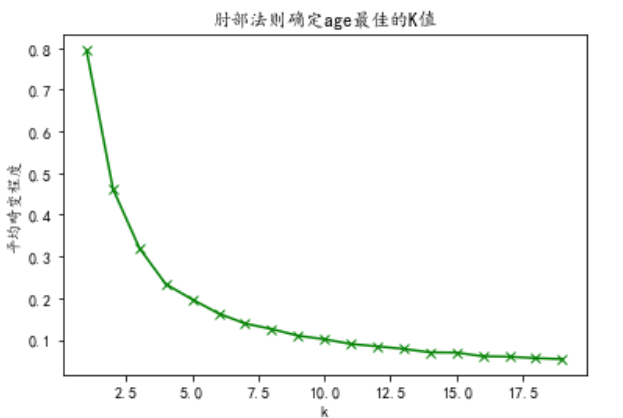
根据随着 k 增加曲线变缓,说明随着 k 的增加,效果提高的越来越不明显,因此可以确定三列的k的属性
1
data_k = [3, 5, 5]
K-means 聚类离散化函数,返回离散化之后列的数据
1
def kmeans_cluster(col, k): # 传入数据和聚类的簇数 kmodel = KMeans(n_clusters=k) # 建立模型 kmodel.fit(col.values.reshape(len(col), 1)) # 训练模型 c = pd.DataFrame(kmodel.cluster_centers_).sort_values(0) # 输出聚类中心,并且排序 # print(c) w = c.rolling(2).mean().iloc[1:] # 相邻两项求中点,作为边界点 w = [col.min() - 1] + list(w[0]) + [col.max()] # 把首末边界点加上 # 这个区间坑死了,居然是前开后闭的 ( ] ,不像 python 中其他的都是前闭后开, # z-score之后数据有负值,因此不能直接使用col.min(),所以首边界需要减 1 # 这个地方网站上的案例都没有注意到,参考了网站案例《Sklearn常用数据预处理方法》介绍 ,里面的也是没有注意到区间的区别 # 结果导致聚类前数据没有nan,聚类之后居然出现了nan # print(w) data = pd.cut(col, w, labels=range(k)) return data

这三列都调用函数,进行离散化
1
for i in range(len(data_col)): col_name = data_col[i] data = data_col_zscore[col_name] # print("聚类前", data.isnull().sum()) data = kmeans_cluster(data, data_k[i]) data.col_name = col # print("聚类后", data.isnull().sum()) credit.update(data) # print(credit[data_col[i]].value_counts())
查看离散化之后的数据
1
credit.head(5)

查看处理之后每列的数据类型个数
1
for col in credit.columns: print("列名:" + col + ", 有", credit[col].value_counts().shape[0], "种类型")
列名:checking_balance, 有 4 种类型 列名:months_loan_duration, 有 3 种类型 列名:credit_history, 有 5 种类型 列名:purpose, 有 10 种类型 列名:amount, 有 5 种类型 列名:savings_balance, 有 5 种类型 列名:employment_length, 有 5 种类型 列名:installment_rate, 有 4 种类型 列名:personal_status, 有 4 种类型 列名:other_debtors, 有 3 种类型 列名:residence_history, 有 4 种类型 列名:property, 有 4 种类型 列名:age, 有 5 种类型 列名:installment_plan, 有 3 种类型 列名:housing, 有 3 种类型 列名:existing_credits, 有 4 种类型 列名:job, 有 4 种类型 列名:dependents, 有 2 种类型 列名:telephone, 有 2 种类型 列名:foreign_worker, 有 2 种类型 列名:default, 有 2 种类型相关性分析
生成相关性矩阵
1
import seaborn as snscredit_coor = credit.corr()credit_coor.head(5)

画出热力图
1
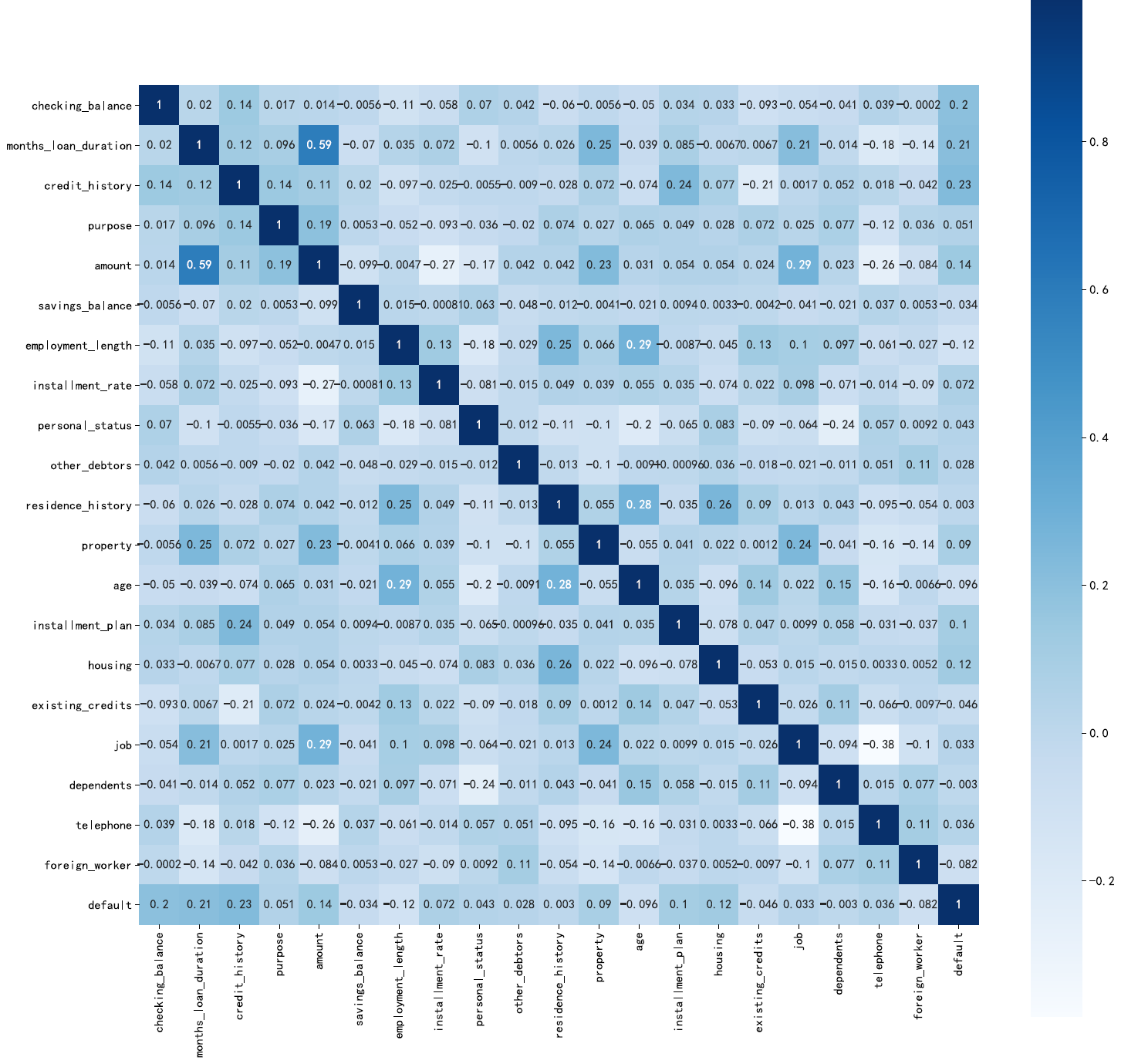
plt.subplots(figsize=(18,18),dpi=720,facecolor='w')# 设置画布大小,分辨率,和底色fig=sns.heatmap(credit_coor,annot=True, vmax=1, square=True, cmap="Blues", fmt='.2g')#annot为热力图上显示数据;# fmt='.2g'为数据保留两位有效数字,square呈现正方形,vmax最大值为1fig
从图上可以看出相关性都不是很强,最大的还不到0.6,因此我选择了忽略,不删除任何列
三、模型训练
划分测试集和训练集
1
from sklearn import model_selectiony = credit['default']#del credit['default']X = credit.loc[:,'checking_balance':'foreign_worker']X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y, test_size=0.3, random_state=1)
查看训练集和测试集中违约贷款比例是否接近
1 | print (y_train.value_counts()/len(y_train))print (y_test.value_counts()/len(y_test)) |
1 0.6942862 0.305714Name: default, dtype: float641 0.7133332 0.286667Name: default, dtype: float64
可见比较接近,可以直接使用
模型训练
这里我选用的是多项式的模型,因为之前使用离散化都弄成离散的数据了,所以使用多项式比较好
1
from sklearn.naive_bayes import MultinomialNBcredit_model = MultinomialNB()credit_model.fit(X_train, y_train)
1
MultinomialNB()
使用测试集进行测试
1
credit_pred = credit_model.predict(X_test)
对模型进行评价
1 | from sklearn import metricsprint (metrics.classification_report(y_test, credit_pred))print (metrics.confusion_matrix(y_test, credit_pred))print (metrics.accuracy_score(y_test, credit_pred)) |
precision recall f1-score support 1 0.78 0.88 0.83 214 2 0.56 0.37 0.45 86 accuracy 0.74 300 macro avg 0.67 0.63 0.64 300weighted avg 0.72 0.74 0.72 300[[189 25] [ 54 32]]0.7366666666666667
可见模型的准确率为 $ 73.7\% $ ,但是违约的 recall 值比较低,说明对违约贷款的识别能力比较差。朴素贝叶斯中多项式模型参数比较少,不能更通过灵活的调参提高准确率。如果像上次实验中使用代价矩阵应该可以提高 $ 2 $ 的 recall 值。
四、实验总结
通过本次实验,我了解了朴素贝叶斯的相关用法。朴素贝叶斯分类在参数调整上选择有限,重心应该放在数据的预处理。在实验中使用 K-means ,也练习了 K-means 的用法。但是模型 recall 值感觉比较低,需要进一步使用属性权值进行优化。